>adlucere@admin:~$ introduction.sh
Introduction
In the current age of easy access to humanity's greatest cinematic achievements when we like and how we like, we often wish to seek out the best of the best when looking for a way to spend an afternoon. But what really makes a movie a critical success? Is it an artistic X factor, the result of a director, the cast and the crew pouring their heart and soul into a project, or are there measurable factors that influence if we see a film as "high quality"? Is there a recipe for a critical darling? In this project we attempt to gain a deeper understanding of what makes a movie a critical success using a data-driven approach. Our analysis takes into account several factors and takes advantage of the large amounts of lexical data provided in the data set using feature extraction.
What makes a movie successful? Can we profile successful movies?
Come forth red carpet of analytical results...
>adlucere@admin:~$ cat introduction.log
Data Cleaning & Exploration
The dataset we work on is the CMU movie summary corpus dataset. We analyze the movies based on their average IMDb rating with respect to their release date, their availability in certain languages and countries, and the presence of the most prevalent genres. Additionally, we also take into account the main actor's gender proportion.
>adlucere@admin:~$ data_preprocessing.sh
... CMU meta data merging on movie. Process feature encoding ...
... Take most representative occurrences language, country genre ...
... Merge resulting dataset with imdb score ...
... Generate final dataset ...
Done !
>adlucere@admin:~$ cat exploratory_analysis.log
Exploratory Visualizations
Lets take a look at the processed data:
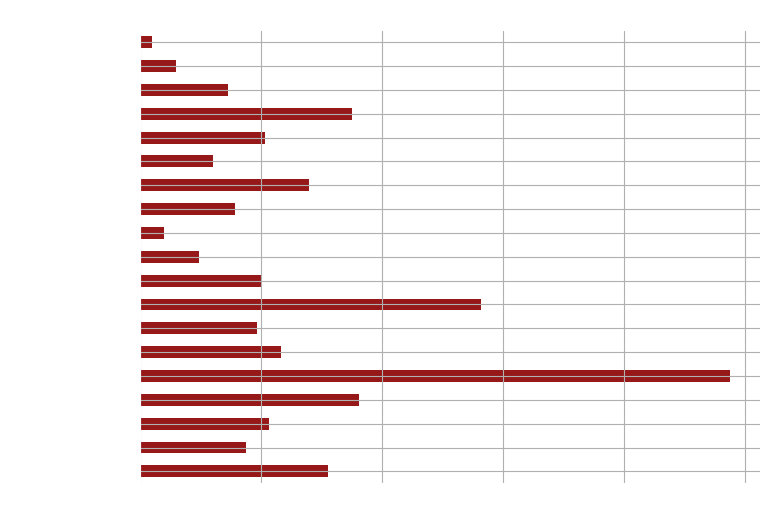
It is evident from the genre proportions that half of the films have dramatic settings, a third of them are comedies, and a further third are dramas and romantic films, respectively. Lower percentages of movies are found in the other genres, with Silent Films having the lowest movie proportional.
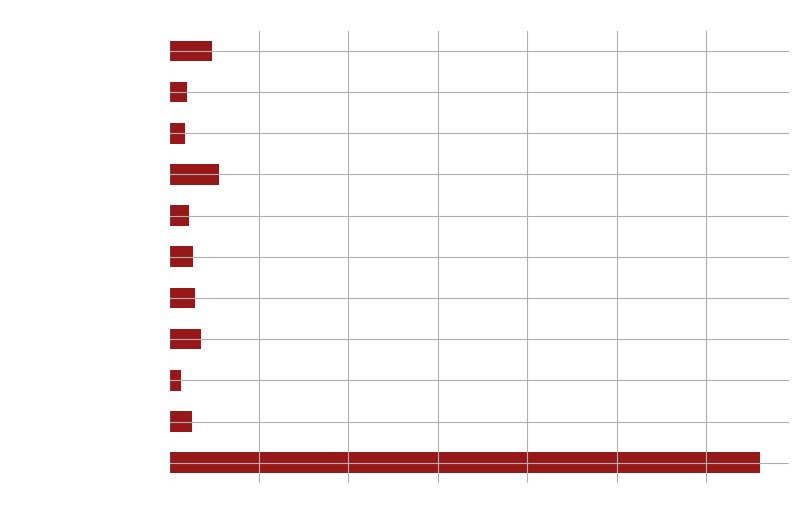
The distribution of languages in the movies as shown demonstrates that English is used in more than 70% of the movies, followed by Hindi and French. Regarding the others, it appears that local movies are the only ones that use these languages.
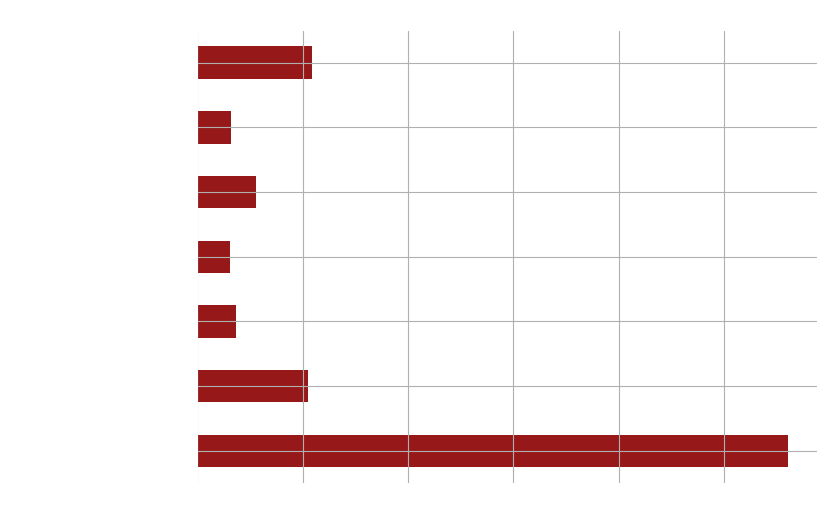
The majority of our films are produced in the United States, followed by a similar number of films in India and the United Kingdom, with fewer films being produced in Japan.
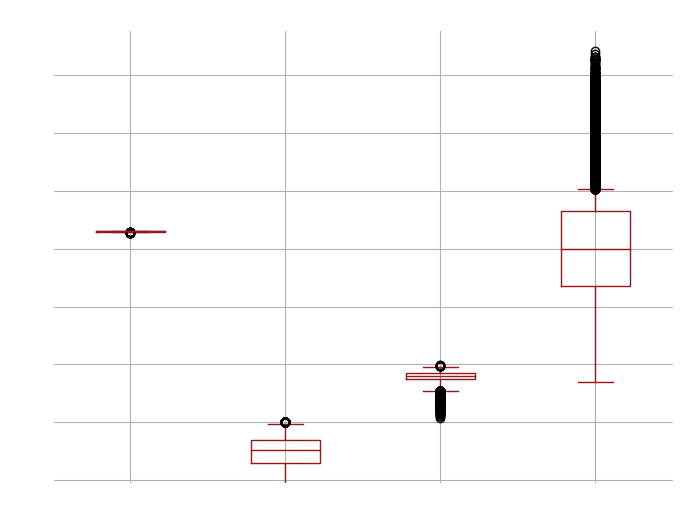
According to the results, the release date for each movie is essentially the same and hasn't changed at all in terms of exponential scale. On the other hand, we see that the numVoters has a wider range of values among the films, and there are some films that may be more well-known that have more voters referred to in the plot as outliers.Regarding the gender distribution across movies, we observe a consistent pattern with a mean of 50% equality; nevertheless, one film that features solely female actors stands out.We also have a normal distribution for the ratings, but this time there are more outliers with lower ratings on a log scale.
Now what about plot summaries..?
>adlucere@admin:~$ nlp_processing_pipeline.sh
NLP preprocessing pipeline
... performing stopword filtering ...
... lemmatization and punctuation removal ...
... starting word cloud visualization ...

>adlucere@admin:~$ cat latent_dirchlet_allocation_analysis.log
Latent Dirichlet Allocation
After the preprocessing phase on plot summaries, our approach was to include bigrams in the dictionary of our corpus to train a LDA model in order to find the topic distributions over the movie plot summaries. We used the coherence score to compare the models in order to fine-tune the topic parameter for the LDA technique, and in the end we chose the model with the lowest score when the curve will exactly have an upward slope. As the most common words associated with a topic are often difficult to interpret, we also extract a list of "prototype" movies for each topic, namely the top five weighted probability movies on each topic based on the movie-topic matrix distribution. We use pyLDAvis for interactive visualization.
So what is behind the LDA model findigs? What does this generated topics tell us?
Topic 1: Romantic comedy-dramas with a twist
We easily discovered some common threads between the prototypes for each topic. For topic 1, the prototypes have a great variety of release dates and localizations and are often romantic movies with a combination of comedy and drama elements. Additionally, they seem to have surprising elements, involving sensitive topics such as abortion after an accidental teen pregnancy or surreal elements, such as a movie character begging his writer for a companion. Because of this we choose the label Romantic comedy-dramas with a twist for this topic. Below are some of the most representative movies.



Topic 2: International historical movies
Continuing the above logic, the topic 2 prototypes are historical movies, generally set during events of upheaval and adversity, such as wars or terrorist hijackings. The most weighted tokens findings from LDA are the 'kill' ,'soldier','army','war'. Despite that fact, the prototypes do not seem to contain mainstream Hollywood American war movies. We therefore assign the label International historical movie to this category. Below are some of the most representative movies.



Topic 3: Low-budget action movies
Regarding topic 3, there wasn't a single exemplary approach to describe the prototype movies because there were contextual variations in both the weighted tokens and the summaries. The probability from the LDA model captures that the prototypical movies for this category have a 69% maximum chance of being about this subject, meaning that they cannot fully depict the context of the topic. However, a common thread in the prototypical movies seems to be violence and the presence of crime, cowboys, or the police as a central theme. Additionally, most of the prototypes are B-movies or independently produced. In light of this, we chose the label Low-Budget Action Movies for this topic.


Topic 4: Classical American cartoons
The most prevalent words in Topic 4's LDA outputs, as you can observe from the interactive plot, are seemingly meaningless words and a lot of names. However, a closer look at the prototypes themselves reveals that they are all Warner Brothers cartoons from the 1960s, so we chose the label Classical American Cartoons.



>adlucere@admin:~$ lda_vis.sh
... LDA visualization booting ...
... Done!
LDA Visualization
An interactive widget is generated using pyLDAvis, for deeper knowledge about topic interpretation such as word distribution between topics play with the following application.
>adlucere@admin:~$ cat factor_analysis.log
Factor Analysis
We are able to make three significant separations of the movies based on plot summaries depending on whether they “belong” to one of 3 computed categories named factors. Each movie can only be assigned to one of them.
Will this separation be useful to distinguish between successful and unsuccessful movies?
Now that we have three different groups of movies, let's see how different they are from each other. And more importantly, if they give us any important insight on our objective, average imdb rating score.
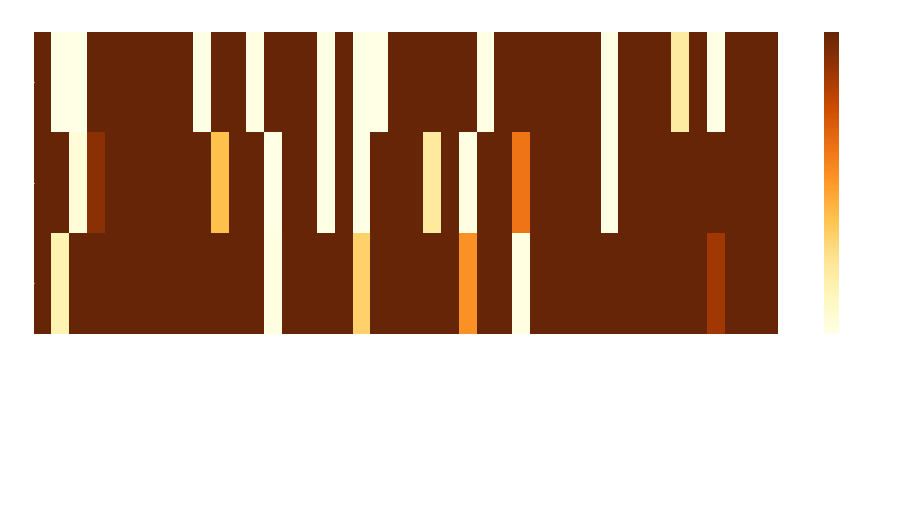
T-tests are made on mean proportions for our categorical variables and means for the numeric variables. We deem significatively different those features whose t-tests p values are below the corrected significance 0.00041. It can be observed that this factor assignment yields significant differences between the groups, hence, we can consider them different. However, we observe that even though they may be a meaningful representation of the plot summaries, they do not have clear differences in their average rating.
They do not provide information for our end goal: profiling success in movies.
What about plot summaries then?
We executed two different transformations on the plot summaries and got meaningful representations of them. These representations or encodings are included in the following analysis, and should be taken into account when defining the characteristics that make a movie successful (high IMDb rating).
>adlucere@admin:~$ cat imbd_score_separation_analysis.log
Statistical IMDB Score Analysis
As the theme of our project is hacking the Oscars, we do not wish to simply discover correlations
between features and IMDB ratings, but establish statistical differences between the very highest
rated movies and the rest. For that we first discretize the imdb average rating into 5 quantiles
analogously to ratings in terms of number of stars. We then split the dataset into two categories:
movies with 5-star ratings and movies with ratings below 5 stars.
First, we conduct t-tests to determine if the difference in the mean values of the features between
5-star and non-5-star movies is statistically significant. Due to the high number of comparisons this
involves, a correction for the usual p-value of 0.05 must be used. As we cannot reasonably assume
statistical independence between the features (e.g. english_language and USA are likely highly correlated),
we choose the more conservative Bonferroni correction.
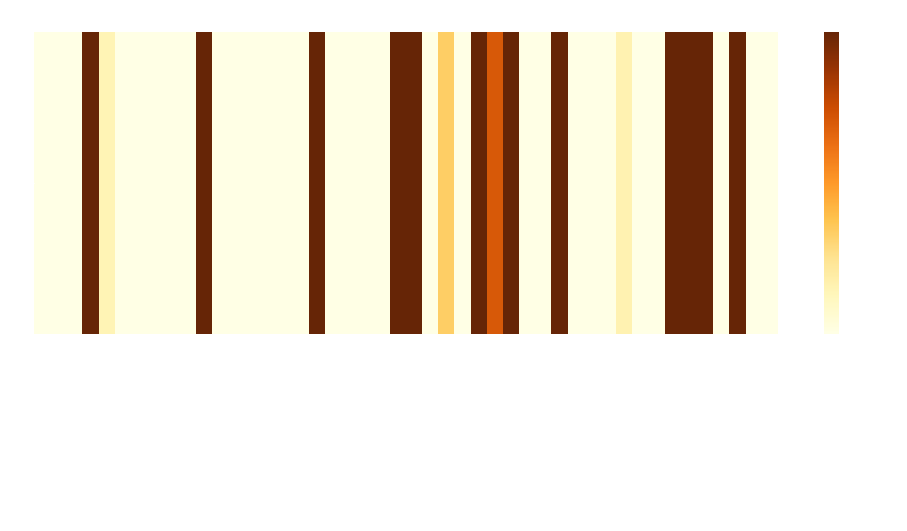
Even with this conservative correction, a large majority of the features are statistically significant. This is unsurprising due to the size of the dataset and the nature of the features, however it is not helpful for our analysis. We therefore sort the features by increasing order of p-value.
Feature |
P value |
|---|---|
united_states_of_america |
4.371e-95 |
Drama |
1.031e-91 |
english_language |
1.754e-85 |
Horror |
5.943e-72 |
india |
3.866e-70 |
World_cinema |
1.441e-66 |
Short_Film |
9.942e-53 |
topic_3 |
3.263e-50 |
Documentary |
9.457e-47 |
Action |
1.920e-28 |
This already gives us an idea of which features are likely to play an important role in the success of a movie, but we still need to find the magnitude or sign of the effect. Due to the high number of features we do not immediately conduct a detailed analysis on all of them. Instead, we filter out the features most likely to have a strong effect on success by analyzing the mean differences between the features after standardization.
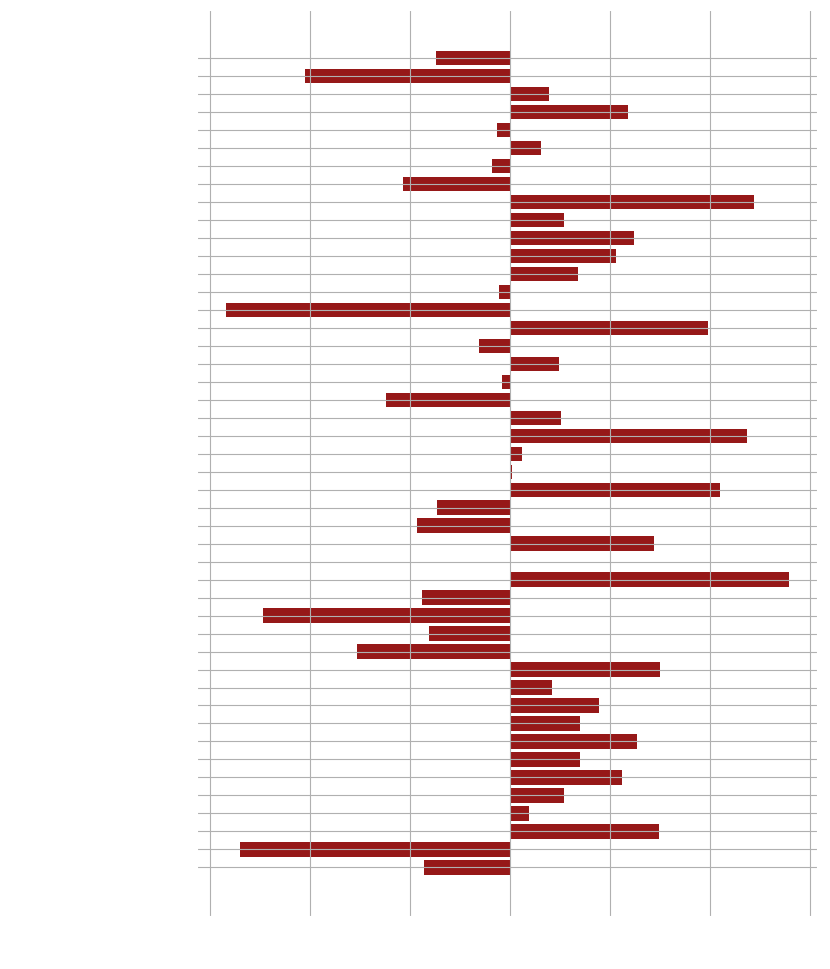
As a side note, we remark that a noticeable gender bias is present in the data, with movies that cast a lower proportion of women being more critically successful. After a quick analysis, this effect is confirmed to be statistically significant with a magnitude of approximately 0.03. However, we exclude this feature from our recommendations for increasing movie success due to ethical considerations.
Moving on to results we could actually use, we extract 10 features with the largest positive and negative mean differences.
Feature |
Mean difference |
|---|---|
Drama |
0.2792 |
india |
0.2436 |
World_cinema |
0.2371 |
Short_Film |
0.2104 |
Documentary |
0.1977 |
french_language |
0.14978 |
german_language |
0.1491 |
black_and_white |
0.1437 |
tamil_language |
0.1266 |
france |
0.1235 |
Feature |
Mean difference |
|---|---|
united_states_of_america |
-0.2844 |
english_language |
-0.2694 |
Horror |
-0.2468 |
topic_3: low-budget action movies |
-0.2051 |
Action |
-0.1524 |
Action/Adventure |
-0.1234 |
F_gender |
-0.1066 |
Comedy |
-0.0934 |
Thriller |
-0.0887 |
release_date |
-0.0855 |
In the subsequent analysis, we consider only the most important features appearing in these two lists for languages and countries of production, whereas for genres, we only consider those having the most significant positive effect.
Effect of production country and language
As the features of language and country of production are closely related, we analyze the pairs with the most potential for a significant effect , that is USA-English, India-Tamil, France-French and Germany-German. We also note that English is not only an official language in the USA, but also in India. However, for simplicity and considering the dominance of Hollywood, we associate English with USA in our analysis.
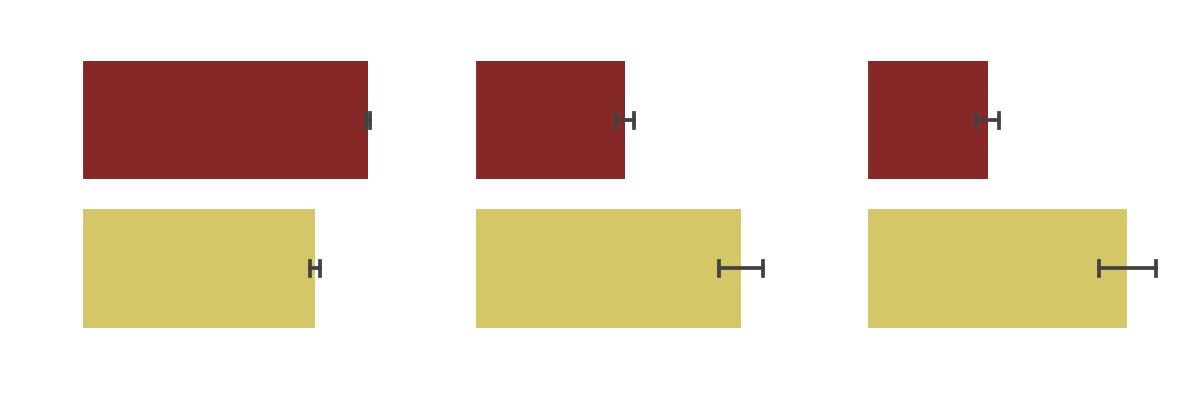
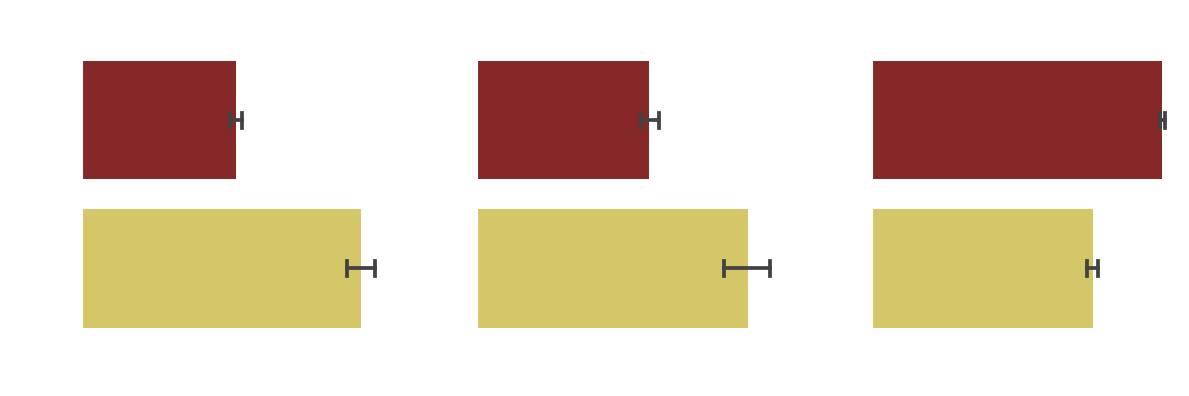
Our analysis confirms that English movies made in the USA fare worse in the IMDB ratings, whereas Indian movies in Tamil fare much better, as well as French and German movies.
Effects of genre
The 4 genres with the highest positive mean difference are Drama, World Cinema, Short Film and Documentary.
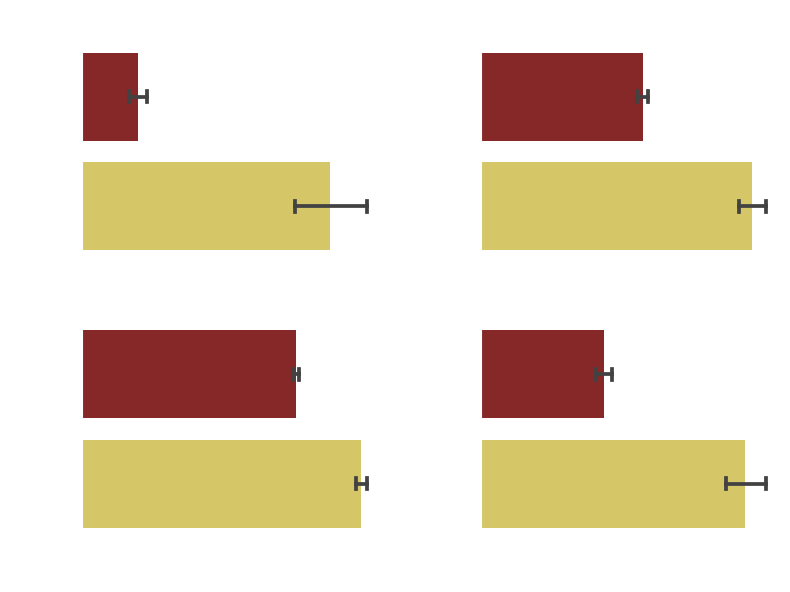
We conclude that those 4 genres do indeed have a positive and statistically significant correlation to critical acclaim. It should be noted that although at first glance the documentary genre seems to have the highest impact, this is only true for the relative difference. Indeed, the proportion of documentaries in the dataset is quite small and in terms of absolute difference, dramas seem to have an even higher impact.
Effects of topics (LDA)
Due to the limited number of topics generated by the LDA analysis we analyze all of them.
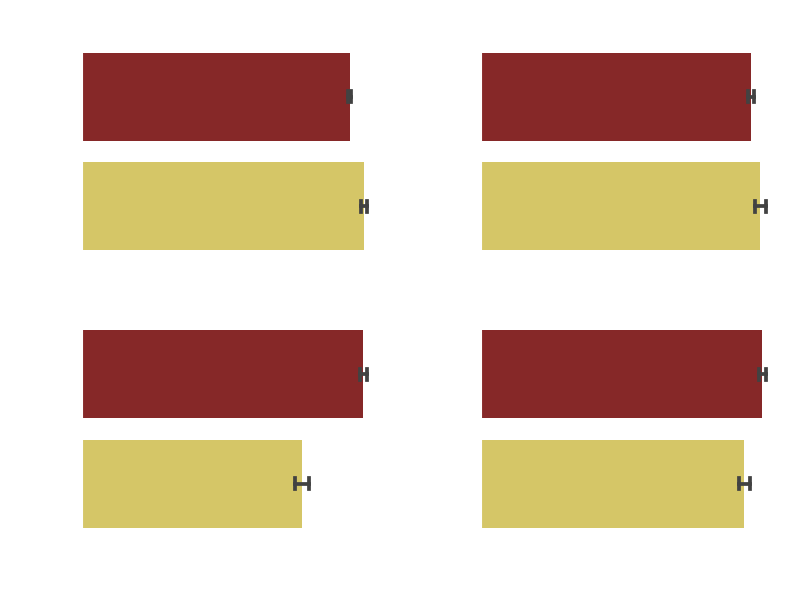
We observe that the effect of topic 2 (International historical movies) is not necessarily statistically significant. The topic 1 (Romantic comedy-dramas with a twist) has a small but statistically significant effect, whereas topic 4 (classical American cartoons) and topic 3 (low-budget action movies) have a significant negative effect. Due to the nature of these topics, the results are not surprising, however they are not necessarily as useful for our recommendations as existing features in the dataset.
Effect of factors
We see that none of the factors have a statistically significant effect.
>adlucere@admin:~$ cat conclusions.log
Conclusions
Based on our research, we propose the following suggestions to anyone looking to make a movie specifically
catering to the tastes of the IMDB userbase.
First of all, do not make the movie in English language or in the USA.
There is likely a certain aversion towards
the dominance of Hollywood as evidenced by the success of non-english languages like Tamil , French and German,
or the genre of World Cinema Nevertheless, this recommendation should be considered with care and critical thinking.
Indeed, we cannot ethically recommend trying to appropriate another language and culture without knowing anything about
them in order to boost a movie's approval. As a matter of fact, this could lead to controversy, critical backlash and
an empty and flat movie. Instead, we would like to encourage and promote movie directors outside the
English-speaking world that make movies without trying to cater to English-speaking western audiences, as this approach
is likely to lead to better critical recognition in the end.
Secondly, documentaries and dramas seem to perform well in terms of critical success. This is likely due to them being
perceived as more “serious” than genres such as horror or action. As an addition, the short film format seems to surprisingly
have a positive impact. We think this is the most easily implementable recommendation for someone trying to use a data-driven
approach to increase their movies IMDB score. It should be noted that our recommendation differs significantly from the highest
rated movies on IMDB, which consist of high-budget long Hollywood blockbusters like The Godfather or The Dark Knight.
It is possible that our proposal might lead to more modest but consistent gains in approval from the IMDB database.
This leads us to consider the small positive effect that the “Romantic Comedy-Drama with a twist” had on IMDB ratings. Although
the effect is small, it raises an important question with regards to our data-driven approach. The prototypical movies for this
topic presented a surprising amount of variety with regards to where and when they were made. Based on their plot summaries,
they were also arguably among the most stereotype-breaking and original, maybe even the most artistic among the movies we analyzed.
On the flipside, trying to optimize for critical success has led in the past to phenomena such as Oscar-baiting and encourages the
use of proven formulas instead of creativity. Recognizing that our recommendations, if adopted by creators, could create uniform and
boring documentaries devoid of deeper meaning.
We would like to contextualize our project not so much as serious advice to movie makers, but as an interesting data-driven examination
of the tastes of IMDB users. In the end, wouldn't cinema be better off with 1 brilliant movie and 9 terrible ones, rather than 10 uniformly
mediocre pieces trying to out-optimize each other?
>adlucere@admin:~$ cat awards.log
... aand the EPFL Oscar 2022 goes to ...
